The purpose of the following query is to retrieve the top 100 Referrers based on the visit count.
Table SUMSNRefV3_DF2K3010 has the visit counts and contains some 3,500,000 rows, of which some 25,000 belong to the selected user, and some 5,000 distinct referrers.
Table URefsS_DF2K3010_final has the corresponding labels and contains some 2,800,000 rows, of which some 290,000 belong to the selected user. Also, it is important to know that it has a compound (clustered) primary key on (ur_SiteID, ur_Hash, ur_Volgnr).
Please note that table URefsS_DF2K3010_final is outer joined on its Primary Key, and has no effect on the grouping or the TOP 100 selection.
Table SUMSNRefV3_DF2K3010 has the visit counts and contains some 3,500,000 rows, of which some 25,000 belong to the selected user, and some 5,000 distinct referrers.
Table URefsS_DF2K3010_final has the corresponding labels and contains some 2,800,000 rows, of which some 290,000 belong to the selected user. Also, it is important to know that it has a compound (clustered) primary key on (ur_SiteID, ur_Hash, ur_Volgnr).
SELECT TOP 100 MIN(ur_Referrer) AS Label ,SUM(COALESCE(Bezoeken,0)) AS Aantal FROM netpoll.SUMSNRefV3_DF2K3010 LEFT JOIN netpoll.URefsS_DF2K3010_final ON ur_SiteID=@pnUserID AND ur_Hash =ReferrerHash AND ur_Volgnr=ReferrerVolgnr WHERE SiteID =@pnUserID AND FolderID=@pnFolderID AND DGWID =0 GROUP BY ReferrerHash, ReferrerVolgnr ORDER BY Aantal DESC
SQL Server 7.0
So let's see what SQL Server 7.0 did:
Now why does it do a Hash Match? That is because it does a very inefficient seek/scan of the index on URefsS_DF2K3010_final. It does not use the full compound key to seek corresponding rows (not even when forced), but only seeks on the leading column:
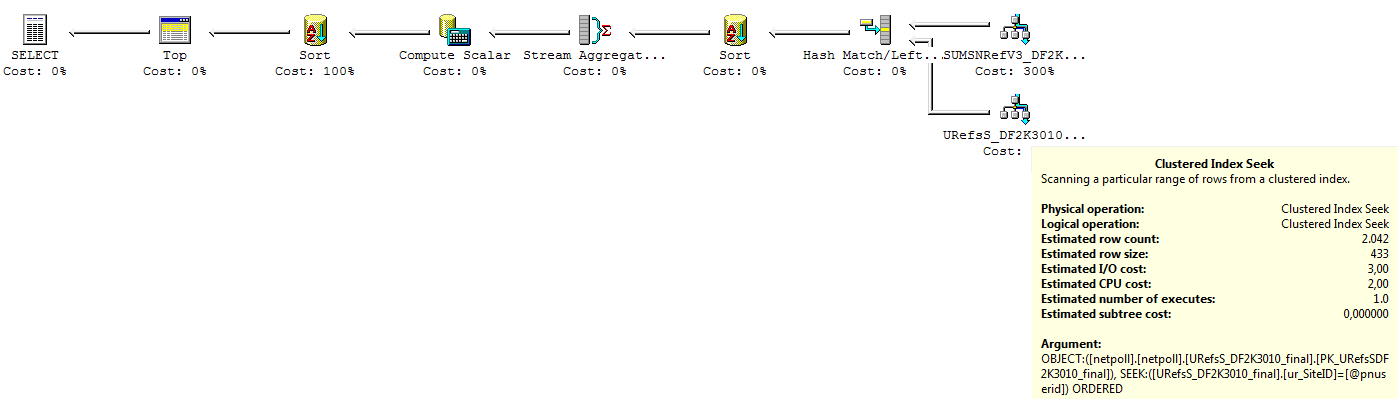
Because of that, it will read 290,000 rows from URefsS_DF2K3010_final, instead of only finding the 100 desired labels.
SQL Server 2000
Fortunately, when SQL Server 2000 came along, it easily figured out that it would be faster to seek the Label for each of the 25,000 qualifying rows:
Now, it does seek on the full compound primary key. The cost is still relatively high, because this way, there are still some 25,000 seeks executed.
SQL Server 2005
SQL Server 2005 only does slightly better:
It still has to execute 25,000 seeks. But since the resultset is sorted, all duplicates will be cached. Also, the access to table URefsS_DF2K3010_final will be as sequential as it gets, which should also benefit performance (in a cold cache situation).
Optimal solution
Getting the optimal query plan requires a rewrite. The optimal solution would group first, then select the TOP 100 rows, and only then join with URefsS_DF2K3010_final to get the corresponding labels.The rewrite can look like this:
SELECT ur_Referrer AS Label ,T1.Aantal AS Aantal FROM ( SELECT TOP 100 ReferrerHash ,ReferrerVolgnr ,SUM(COALESCE(Bezoeken,0)) AS Aantal FROM netpoll.SUMSNRefV3_DF2K3010 WHERE SiteID =@pnUserID AND FolderID=@pnFolderID AND DGWID =0 GROUP BY ReferrerHash, ReferrerVolgnr ORDER BY Aantal DESC ) AS T1 LEFT JOIN netpoll.URefsS_DF2K3010_final R2 ON R2.ur_SiteID=@pnUserID AND R2.ur_Hash =T1.ReferrerHash AND R2.ur_Volgnr=T1.ReferrerVolgnr ORDER BY Aantal DESC

The resulting query plan looks very good. It only requires 100 seeks (some 300 logical reads). And with a hot cache, it cut the duration by 60%.
We will see when SQL Server's optimizer is smart enough to do this rewrite. Maybe in 2008?