Many developers use
However, in general this is not a smart thing to do, and in some situations it is downright dangerous (in the long run)!
This article explains why it is a bad idea to use
SELECT * to select all columns of a particular table. Typing
SELECT * FROM ... is much simpler and less work than typing say
SELECT order_id, order_date FROM ....However, in general this is not a smart thing to do, and in some situations it is downright dangerous (in the long run)!
This article explains why it is a bad idea to use
SELECT * in production code.
Main reasons
The main reasons not to useSELECT * are:
- Performance might suffer
- Table changes can lead to unexpected behavior and errors
As usual there are always exceptions.
Setup
The examples in this article use a few tables. The setup for it, as well as some sample data is shown below.
-- DROP VIEW dbo.complete_orders
-- DROP TABLE dbo.orderlines
-- DROP TABLE dbo.orders
CREATE TABLE dbo.orders
(order_id int NOT NULL CONSTRAINT PK_orders PRIMARY KEY NONCLUSTERED
,order_date datetime NOT NULL
,description char(300) NULL
,shipped_date datetime NULL
,amount_paid decimal(15,2) NULL
,full_info varchar(max) NULL
,cs XML column_set FOR ALL_SPARSE_COLUMNS
)
CREATE INDEX IX_orders_orderdate ON dbo.orders(order_date) INCLUDE (order_id)
CREATE TABLE dbo.orderlines
(orderlines_order_id int NOT NULL CONSTRAINT FK_orderlines_orders REFERENCES dbo.orders
,line_number tinyint NOT NULL
,article_number int NULL
,amount tinyint NULL
,price decimal(15,2) NULL
,last_change_date datetime NULL
,CONSTRAINT PK_orderlines PRIMARY KEY CLUSTERED (orderlines_order_id,line_number)
)
INSERT INTO dbo.orders(order_id,order_date,amount_paid,full_info) VALUES (1,'20100801',14,REPLICATE('a',100000))
INSERT INTO dbo.orders(order_id,order_date,amount_paid,full_info) VALUES (2,'20100802',14,REPLICATE('b',200000))
INSERT INTO dbo.orders(order_id,order_date,amount_paid,full_info) VALUES (3,'20100803',14,REPLICATE('c',300000))
INSERT INTO dbo.orders(order_id,order_date,amount_paid,full_info) VALUES (4,'20100804',14,REPLICATE('d',400000))
INSERT INTO dbo.orders(order_id,order_date,amount_paid) VALUES (5,'20100805',15)
INSERT INTO dbo.orders(order_id,order_date,amount_paid) VALUES (6,'20100806',9.95)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number) VALUES (1,1)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number) VALUES (1,2)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number) VALUES (2,1)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number) VALUES (3,1)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number) VALUES (3,2)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number) VALUES (3,3)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number) VALUES (4,1)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number,amount,price) VALUES (5,1,4,2.50)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number,amount,price) VALUES (5,2,1,5)
INSERT INTO dbo.orderlines(orderlines_order_id,line_number,last_change_date) VALUES (6,1,'20100806')
INSERT INTO dbo.orderlines(orderlines_order_id,line_number,last_change_date) VALUES (6,2,'20100807')
Unnecessary extra reads
When you are usingSELECT * you ask for all columns.
-- Select orders in date range -- include I/O statistics SET STATISTICS IO ON GO SELECT * FROM orders WHERE order_date BETWEEN '20100802' AND '20100805' GO SET STATISTICS IO OFF
Now, our test table has a
varchar(max) column in it. This data is (normally) not stored
on the same disk page that holds the rest of the column data, but it is stored in lob (Large Object) pages.This is true for all large-value data types, such as
varchar(max), nvarchar(max),
varbinary(max),
text, ntext and image. The only exception is when the actual data
in the column is so small that it would fit on the same page as the rest of the columns, and the table
configuration allows inline storage of lob columns.In the test setup of this article, any lob column that is filled has a value that requires more than 8060 bytes, so they can never be (completely) stored inline.
If you run the query above, it will show this line below the query resultset.
Table 'orders'. Scan count 1, logical reads 1, physical reads 1, read-ahead reads 0, lob logical reads 7, lob physical reads 3, lob read-ahead reads 0.
If you don't need all columns, and you just select the ones you need, the storage engine can avoid retrieving the lob column data.
-- Select orders in date range; relevant columns only -- include I/O statistics SET STATISTICS IO ON GO SELECT order_id, order_date, amount_paid FROM orders WHERE order_date BETWEEN '20100802' AND '20100805' GO SET STATISTICS IO OFF
Table 'orders'. Scan count 1, logical reads 1, physical reads 1, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table Scan instead of Index Seek
When you are usingSELECT * you ask for all columns.
-- Select orders in date range SELECT * FROM orders WHERE order_date BETWEEN '20100802' AND '20100805'
A typical query plan for a query like that is a table scan.
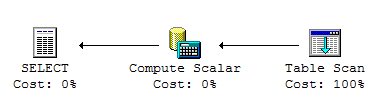
If you don't need all columns, and you just select the ones you need, the optimizer might be able to come up
with a more efficient query plan.-- Select orders in date range; relevant columns only SELECT order_id, order_date FROM orders WHERE order_date BETWEEN '20100802' AND '20100805'
The nonclusted index IX_orders_orderdate is very useful for this query. It covers the requested columns,
and it is able to efficiently apply the WHERE clause
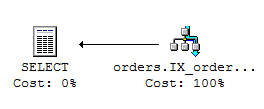
This query plan will be significantly faster, especially when the table grows and/or when a smaller percentage of all rows is selected.
This query plan will be significantly faster, especially when the table grows and/or when a smaller percentage of all rows is selected.
Dropping a column that is still in use
You are asked to remove a column from the table. You want to make sure that the column isn't used anywhere. So you search all queries for the column's name, but can't find any. So that is good!But now you find a few instances of
SELECT *. The application that uses these queries,
are they actively using this column, the one that needs to be dropped? You don't know! At least
not until you've investigated these applications as well.If it is still used in an application, dropping the column will break this application.
That fact that the application is broken might not become apparent for quite some time, because it depends entirely on where the query is used, and how errors are handled. Prepare for a confused application developer.
Using SELECT * in a view
You have a view that uses SELECT * to join the orders table and orderlines table into one resultset. Like this:
CREATE VIEW dbo.complete_orders AS
SELECT *
FROM orders
JOIN orderlines
ON orderlines_order_id = order_id
Assume this view has been created in the past. Selecting from the view would look like this:
-- select complete orders of August 5th SELECT * FROM complete_orders WHERE order_date = '20100805'

You are asked to add a column to table orders. What's the harm of adding a column?
Well, let's see what happens if you do.
ALTER TABLE dbo.orders ADD return_date datetime NULL -- select complete orders of August 5th SELECT * FROM dbo.complete_orders WHERE order_date = '20100805'

Notice what's happened to the right of column cs? The value of column return_date is shown in the column names
orderlines_order_id. All other column's values have been moved one column to the right. The column
last_change_date now lists money amounts. Can you see the problems this will cause for the application(s)
that use the view?By the way, if you want to fix the view, then run:
sp_refreshview "dbo.complete_orders"Using SELECT * from multiple tables
You have a query that usesSELECT * to select from multiple tables. Like this:
-- select everything of August 6th SELECT * FROM orders, orderlines WHERE orderlines_order_id = order_id AND order_date = '20100806'

Let's assume the application executing this query is using the column
last_change_date.
With the current query, it would get 2010-08-06 and 2010-08-07.Now let's say your boss asked you to add a
last_change_date column to the orders table as well.
ALTER TABLE orders ADD last_change_date datetime NULL
SELECT * query.-- select everything of August 6th SELECT * FROM orders, orderlines WHERE orderlines_order_id = order_id AND order_date = '20100806'

Notice that application would now only get back NULLs when inspecting
last_date_change.
The orderlines last_date_change column is no longer available, except when using the column's
index number (which would have caused problems in this example as well)!By the way: if you happened to run the previous example - the one with the view - then see what happens now if you run
-- refreshing the view after a table modification sp_refreshview "dbo.complete_orders"
Server: Msg 4506, Level 16, State 1, Procedure sp_refreshsqlmodule_internal, Line 75 Column names in each view or function must be unique. Column name 'last_change_date' in view or function 'complete_orders' is specified more than once.
SPARSE columns
If you have many columns that are NULL most of the time, then it can save a lot of diskspace if you declare them asSPARSE.You have an application that runs this query:
-- select everything of August 6th SELECT * FROM orders, orderlines WHERE orderlines_order_id = order_id AND order_date = '20100806'
Let's assume some thought it would be a good idea to make
amount_paid a sparse column.ALTER TABLE orders ALTER COLUMN amount_paid decimal(15,2) SPARSE NULL
SELECT * query.-- select everything of August 6th SELECT * FROM orders, orderlines WHERE orderlines_order_id = order_id AND order_date = '20100806'

Notice that application will no longer be able to find the
amount_paid column, because
SELECT * will not select it. Instead, the column cs will contain its value
in XML format.Exceptions
As usual, there are always exceptions. In this case there is one.It is no problem at all to have
SELECT *
in an EXISTS clause. Like this:
-- SELECT * in EXISTS() is just fine!
SELECT order_id, order_date, amount_paid
FROM orders
WHERE EXISTS (
SELECT *
FROM orderlines
WHERE orderlines_order_id = order_id
AND amount IS NOT NULL
AND price IS NOT NULL
)
SELECT * in this EXISTS clause
does not actually select any columns. It indicates that the columns don't matter.